Menü
Breadcrumbs
Inhalt
Entwicklung eines Konnektors zur Live-Integration heterogener, nicht-hierarchischer Datenstrukturen in relationale Datenbankmanagementsysteme - NXTM; Entwicklung einer Technologie zur Live-Analyse von Datenströmen hinsichtlich Semantik
Allgemeine Informationen
| Projektnummer | 62295202 |
|---|---|
| Projekttitel laut Förderbescheid | Entwicklung eines Konnektors zur Live-Integration heterogener, nichthierarchischer Datenstrukturen in relationale Datenbankmanagementsysteme - NXTM |
| Akronym | NXTM |
| Projektlaufzeit | 01.11.2014 - 31.10.2016 |
| Forschungsschwerpunkt | Transformationsprozesse in Wirtschaft und Gesellschaft |
| Zuordnung | |
| Kompetenzfeld | Wissens- und Technologietransfer in die Region |
| Themengebiet | Semantische Datenanalyse |
| Grundeinheit | Fakultät Elektrotechnik und Informatik |
| Projektwebseite | http://www.enterprise-application-development.org/projects/nxtm.html |
Inhaltliche Projektbeschreibung
Förderung
![]()
![]()

Kurzbeschreibung
Ziel des Projektes ist es, vernetzte Daten an den Grenzen eines Informationssystems zunächst im Hinblick auf ihre Inhalte und ihre Struktur automatisiert, live im Datenstrom analysieren zu können. Im Anschluss daran sollen die gewonnenen Informationen und ihre Metainformationen dergestalt in einem Datenbanksystem abgelegt werden, dass ihre vernetzte Struktur in Hinblick auf eine spätere Navigation innerhalb des Datenbestandes erhalten bleibt. Die Kernfunktionalität des NXTM Systems basiert auf einer AnalyseEngine, die u.a. das für einen Endnutzer relevante Wissen in den verfügbaren Informationsquellen entdecken soll. Ein Großteil dieser Informationen besteht aus unstrukturierten Daten (z.B. Emails, ForumEinträge, PDF Dateien, Vortragsfolien, MS Office Dokumente), die kein vordefiniertes Datenmodell einhalten, und nur durch Menschen konsumiert werden können. Um es den Computern zu ermöglichen, diese Daten verarbeiten zu können, muss zuerst eine semantische Struktur in den Daten aufgebaut werden. Dieser Prozess erfolgt in mehren Schritten und basiert auf der natürlichen Sprachverarbeitung (NLP Natural Language Processing). Die so erhaltenen strukturierten Daten ermöglichen dann eine vielfältige Informationanalyse, wie zum Beispiel die Identifizierung der bestehenden Vernetzungen zwischen Entitäten im Text und der Erstellung neuer Relationen basierend auf den Linked Data Prinzipien.
Projektübersicht
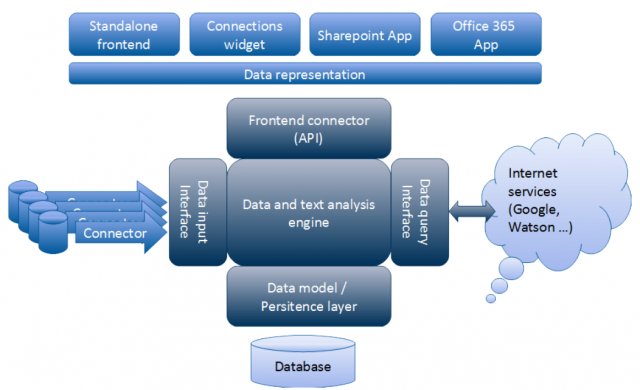
Partner / Kooperationen
|
|
Gesellschaft für Ablauforganisation, Informationsverarbeitung und Kommunikationsorganisation mbH & Co. KG |
Ergebnisse
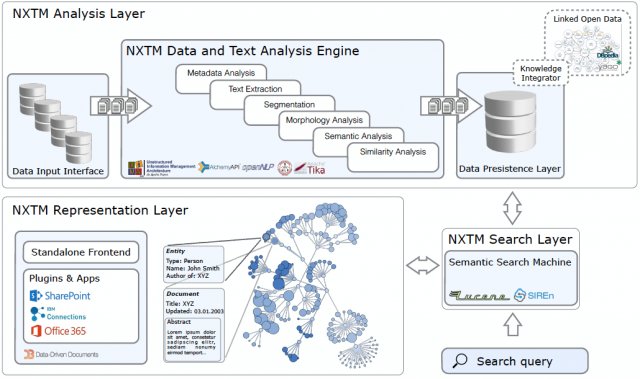
Die aktuellen Ergebnisse der Forschungsarbeit lassen es zu, ein erstes konkretes Bild von der Architektur des Kernmoduls des System für die Datenanalyse zu zeichnen.
Ablauf der Analysephase
Die durch Konnektoren und die Dateneingangsschnittstelle zugestellten Dokumente werden über das Apache UIMA Modul kettenweise verarbeitet:
- Import der vorhandenen Dokumente ins UIMA System,
- Erkennung der Sprache, der MIME-Type und Metadaten über Apache Tika,
- Ausführung des NLP-Analysemodules und Erstellung der Entität-Annotationen (einer der Schritte der semantische Analyse kann über einen externen RESTful basierten Annotator erfolgen),
- Indexierung und Speicherung der Analyseergebnisse für die Stichwortsuche und in einer relationalen oder NoSQL-Datenbank für die weitere Verarbeitung der Metadaten und Annotationen
Zusätzlich wird ein Wissensintegration-Modul gebaut, der als Mapper funktioniert und die neu gewonnenen Informationen mit Linked Open Data Quellen automatisch verlinkt und als RDF Datenmodell in einer Graphdatenbank speichert.
Ablauf der Abfragephase
Während des Suchverfahrens können die Stichwortsuche und die semantische Suche kombiniert werden, d.h. die in der Abfrage anerkannten Entitäten werden in der Graphdatenbank gesucht und dann als Knoten zusammen mit ihren Relationen als Kanten im Graph dargestellt.
Weitere Daten
-
Ansprechpartner
- Herr Prof. Jörg Lässig (Projektleitung)
- Herr Adam Bartusiak
- Herr Marcel Kühne
- Herr Daniel Müssig
- Herr Markus Ullrich
-
Fördermittelgeber
- KF2510009KM4 - BMWi, ZIM, AiF



Finanzierung
- 167.630,00 €
Dokumente
Schlagworte
Zurück zur Übersicht03.08.2026 15:09:40